Bloom filter in Applications
- 2024/11/7
- ブログ
- Comments Off on Bloom filter in Applications

この記事の目次
Let’s started
1. User Existence Check pain point
Nowadays, this problem has become more and more popular in our system. All we do is to use a SQL statement to query a specific record in databases. For example, in the authentication feature, we need to check if the username from request body is existed or not so we probably see a query like below:
| SELECT username, …. FROM accounts WHERE username = ‘…’; |
Let’s break it down a bit.
In most cases, we may have unique constraints or some kind of index on the username field. The database management system (dbms) will analyze the above statement and determine the suitable plan to execute it. In Postgres, the solution should be Index Scan or Index Only Scan which is really fast in this case.
On the other hand, in case that we don’t have any index on the username field, Postgres will perform a Sequential Scan, as known as full table scan, which will traverse all rows of a table to match exactly the where condition. This is a bad use case for our system in the next 3~4 years. Why? Because, when the accounts table becomes large, assume it will have 10m records, the database will take a lot of time to read all records in the accounts table to return only one record. That’s a huge performance problem.
So index saves us one time. But what if there are many requests coming to our server? N requests will have N queries made. Ten million requests will have ten million queries made to the database. Now, the question is can we reduce the number of queries to our database? Yes, we can. We have something called the Bloom Filter to solve this problem.
2. What is Bloom filter?
A Bloom filter is a probabilistic data structure that was introduced in 1970 by Burton Howard. It is now widely used in the fields of search and information storage. This article will explain how Bloom filters work, discuss the trade-offs involved depending on specific use cases, and finally, explore some of their applications.
2.1 How Bloom Filter work
A Bloom filter consists of an array of m binary elements (where each element can be either 0 or 1), and k hash functions designed so that their outputs are integers within the range 1 to m.
Note that the hash functions are not random, they will produce the same output for the same input each time.
For example, a bloom filter with m=16 and k=3:
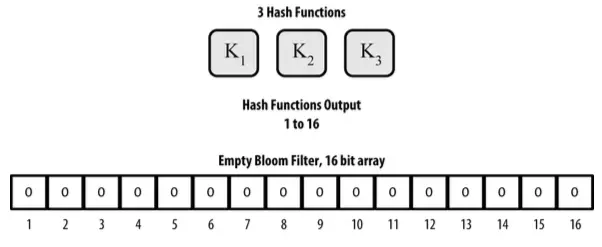
Initially, all the elements in the array are set to 0. To add a record A, A will be passed through the first hash function, and the element corresponding to the hash output (within the range 1 to m) will be set to 1. Similarly, A will be processed through the remaining hash functions.
For example, to add a record A to a Bloom filter:
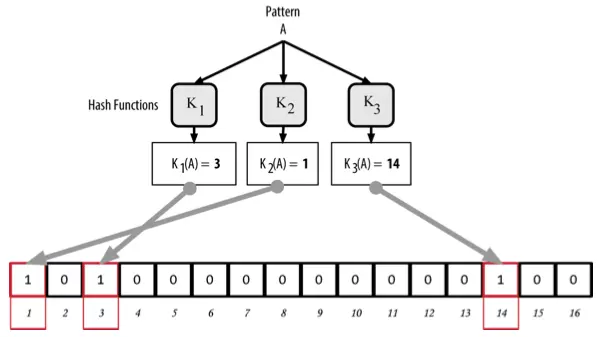
Similarly, when adding a record B to the Bloom filter, the key point here is that if a hash function maps to an index where the value is already 1 (due to a previous record), it will remain 1. Essentially, the more records that are stored in the Bloom filter, the higher the likelihood of overlapping indices, which decreases the accuracy of the filter (this will be discussed further later). This is why Bloom filters are referred to as probabilistic data structures.
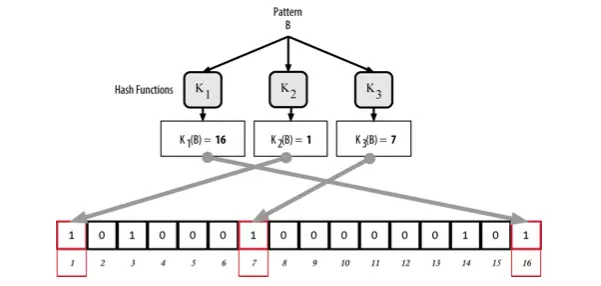
2.2 Searching
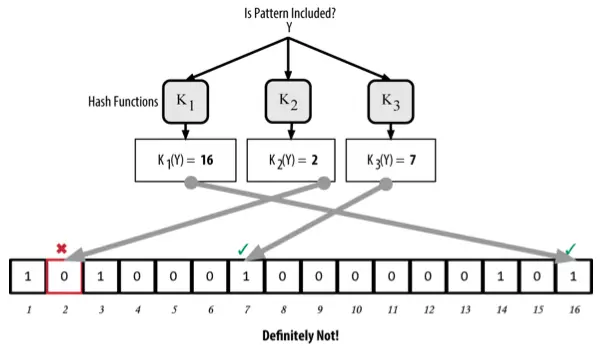
To check if a record X exists in the Bloom filter, X is passed through each of the hash functions in the same way as before. The resulting indices are then checked against the array. If all the corresponding elements have a value of 1, then the record is “likely” stored in the Bloom filter.
The reason for the term “likely” is that an element with a value of 1 could have been set by multiple different records. Therefore, while the Bloom filter indicates the presence of the record, it cannot be absolutely certain. This introduces the possibility of false positives, where the filter incorrectly indicates that a record exists when it does not.
For example, check if a record X exists in the Bloom filter, the result is “likely” existed
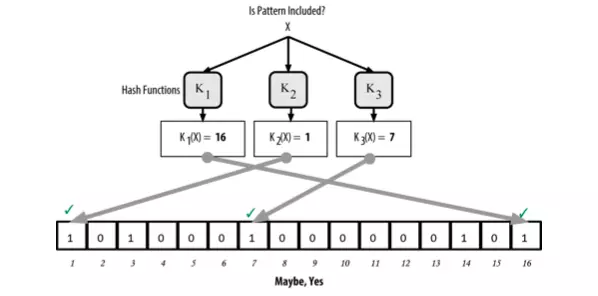
Otherwise, if any element from the hash function’s output has a value of 0, it proves that the record is “definitely not” in the Bloom filter.
3. Trade-off
It can be stated that the accuracy depends on the number of records, the size of the storage array (m), and the number of hash functions (k). In general, increasing the array size and the number of hash functions allows the Bloom filter to store more records with higher accuracy. However, there are certain trade-offs involved. Let’s examine the following cases:
- When m is too small, the proportion of bits with a value of 1 will become large, leading to a higher false positive rate when searching for information. Therefore, increasing the array size can help mitigate this risk, but it will require more storage space.
- When k is too small, the false positive rate will also be high. But if k is too large, it will slow down the process because each record needs to go through too many hash functions (time complexity of O(k)).
4. Conclusion
A Bloom filter is an efficient probabilistic data structure that can be used to quickly check whether an element, such as a user, exists in a large set without requiring significant memory or computational resources. It’s commonly used in scenarios where you need to handle large datasets and can tolerate occasional false positives, but not false negatives.
Imagine a system that needs to check if a user exists in a large, distributed database, such as an authentication service or a recommendation system. Rather than querying the entire database or a central server, which can be slow, a Bloom filter can be used to quickly determine whether a user is likely to be in the set or not.
この情報は役に立ちましたか?
関連記事






カテゴリー:












